적요
Plant germplasm is a part of living genetic resources, including seeds and plant materials, such as roots, leaves, and stems, and should be conserved and managed to maintain ecological biodiversity and to consistently generate the product and supply food crops. Plant germplasm can be categorized based on various genetic traits such as race, and clustering based on similar genetic traits is an efficient method for managing large numbers of germplasms. Therefore, we developed an algorithm, termed cacGMS (Clustering Analysis for Categorical genetic traits of germplasms in Genebank Management System), using categorical variables which statistically differentiate the datatype of genetic traits such as seed-coat color, seed shape, and flower color. Briefly, using Newman’s modularity method, cacGMS combines the hierarchical clustering algorithm using the Ward2 method and representative-based algorithms such as K-medoids, and it regroups all germplasms using germplasm core sets. We tested cacGMS using 2,378 pepper germplasms with 46 different categorical genetic traits, and it exhibited better performance than the hierarchical and K-medoids algorithms for the average distance among clusters (0.4534) and entropy (1.2672). Moreover, cacGMS showed better performance in terms of threshold (from 15 to 30) for genetic traits than other algorithms and provided similar results in a test run using tomato germplasm. From these results, we expect that cacGMS will be a useful tool for managing each group with numerous plant germplasms and facilitate the analysis of other studies, such as analysis of representative characteristics of clustered germplasms and of correlations among germplasms in a particular cluster.
서 언
식물 유전자원(Plant germplasm)은 종자(씨앗)을 포함하여, 뿌리, 잎, 줄기 등과 같이 식물생장이 가능한 영양체를 아우르는 생물자원을 의미하며, 유전적, 형태적 다양성 확보, 활용가치가 높은 유용자원 발굴, 식량자원의 가치 증대, 생태계 유지와 보전에의 기여 등으로 인류에게 있어 매우 중요한 자원이다(
Xepapadeas et al. 2014). 식물 유전자원은 동일 종(Species) 내에서도 다양한 유전형, 표현형에 따른 품종(Race)으로 세분화될 수 있는데, 유전적 차이와 함께 기온, 강수량과 같은 기후영향과 토양의 이화학적 성질, 재배, 수확에 대한 인간활동의 차이 등과 같은 다양한 변화에 따라 식물의 표현형과 유전자형이 유전적으로 차이가 나타난다. 따라서 환경변화에 따라 병 저항성, 해충 저항성 등의 자원 특성에서 안정적 식량생산에 필요한 유용한 형질이 발견될 수 있다(
Nicotra et al. 2010). 이는 식물 유전자원의 확보와 장기적인 보존의 이유와 목적으로, 기후변화 적응, 병 저항성, 작물 생산성이 우수한 신품종 개발과 유용한 형질을 이용한 육종 및 재배기술 등과 같은 농업기술 발전에의 기여, 나아가 생물해적행위(Bio- piracy)로부터 자국의 유전자원과 생물주권을 보호하기 위하여 식물 유전자원의 확보와 관리가 중요하다(
Oh 2014).
다양한 형질의 조합에 의해 표현되는 수많은 유전자원을 보존 및 관리하기 위해서는 자원을 수용할 수 있는 공간과 장기적인 보존을 위한 유지비용, 그리고 전문지식을 갖춘 관리인력이 요구된다. 그래서 수많은 자원에 대한 효율적인 관리를 위한 방법으로 수집된 자원의 초장, 엽색, 종자색, 과형, 과폭, 초형 등과 같은 다양한 형질에 대하여 모든 특성평가 정보를 포함하는 핵심집단(core set or core collection)을 선발하고 핵심집단을 중심으로 관리하는 방법이 통용되고 있다(
Kim et al. 2007,
Moe et al. 2012). 핵심집단은 전체 유전자원의 유전적 다양성을 최대한 포함할 수 있는 최소 자원의 집단을 의미하며, 모든 특성평가 정보를 아우르는 최소의 자원으로 전체 자원의 특성을 관리할 수 있는 장점이 있다(
van Hintum et al. 2000). 그러나 다수의 자원을 이용하여 자원 간 유사성에 기반한 대표성 분석, 형질 간의 상호관계, 형질 변화 패턴, 표현형과 유전자형(genotype)과의 연관성 등과 같은 유전적, 생물학적 연구를 위한 자료로 활용하기에는 제한적이고, 다양한 형질의 조합에 의해 나타나는 자원의 특성을 소수의 핵심집단으로 분석하기에는 어려움이 있다. 따라서 전체 자원에 대한 특성평가 정보를 종합적으로 분석하기 위해서는 자원을 유사한 특성으로 분류하고, 군집단위에서 자원의 대표성을 분석하고 군집 간의 차이를 비교함으로써 장기적인 보존을 위한 자원관리와 신품종 개발, 육종 등에 활용할 자원을 다양한 형질의 상호적인 관계를 고려하여 거시적으로 선택할 수 있는 방법이 필요하다.
본 연구는 다수의 유전자원을 군집하여 유전자원의 분석과 연구목적의 관리에 대한 효율성 증대를 위하여 특성평가 정보를 바탕으로 유사한 특성의 식물 유전자원을 군집하는 알고리즘(cacGMS, Clustering Analysis for Categorical genetic traits of germplasms in Genebank Management System)을 개발하였다. cacGMS는 R-project (
Dessau & Pipper 2008)의 패키지에서 제공하는 Ward2 알고리즘(
Murtagh & Legendre 2014)으로 계산된 트리(tree)를 이용하여 군집하는 계층적 군집(hierarchical clustering)알고리즘과 임의로 선발된 대표객체를 바탕으로 군집을 형성하는 대표객체 기반 군집 알고리즘(representative-based clustering algorithm)인
K-medoids 알고리즘(
Park & Jun 2009)을 통합하고, 핵심집단을 적용하여 유사한 특성을 나타내는 자원의 군집을 생성한다. 본 알고리즘의 성능을 평가하기 위하여 국내 농업유전자원센터(
Kim et al. 2010)의 씨앗은행(genebank.rda.go.kr)에서 제공하고 있는 고추와 토마토 유전자원으로 시험했을 때, 계층적 군집 알고리즘과 대표객체 기반 알고리즘보다 군집간 평균거리와 엔트로피에서 cacGMS알고리즘 성능이 높음을 확인하였다. 따라서 식물유전자원의 특성평가 정보에 대한 분류와 관련한 육종연구 및 자원관리에 있어서 본 알고리즘의 활용도가 높을 것으로 기대된다.
알고리즘 및 평가방법
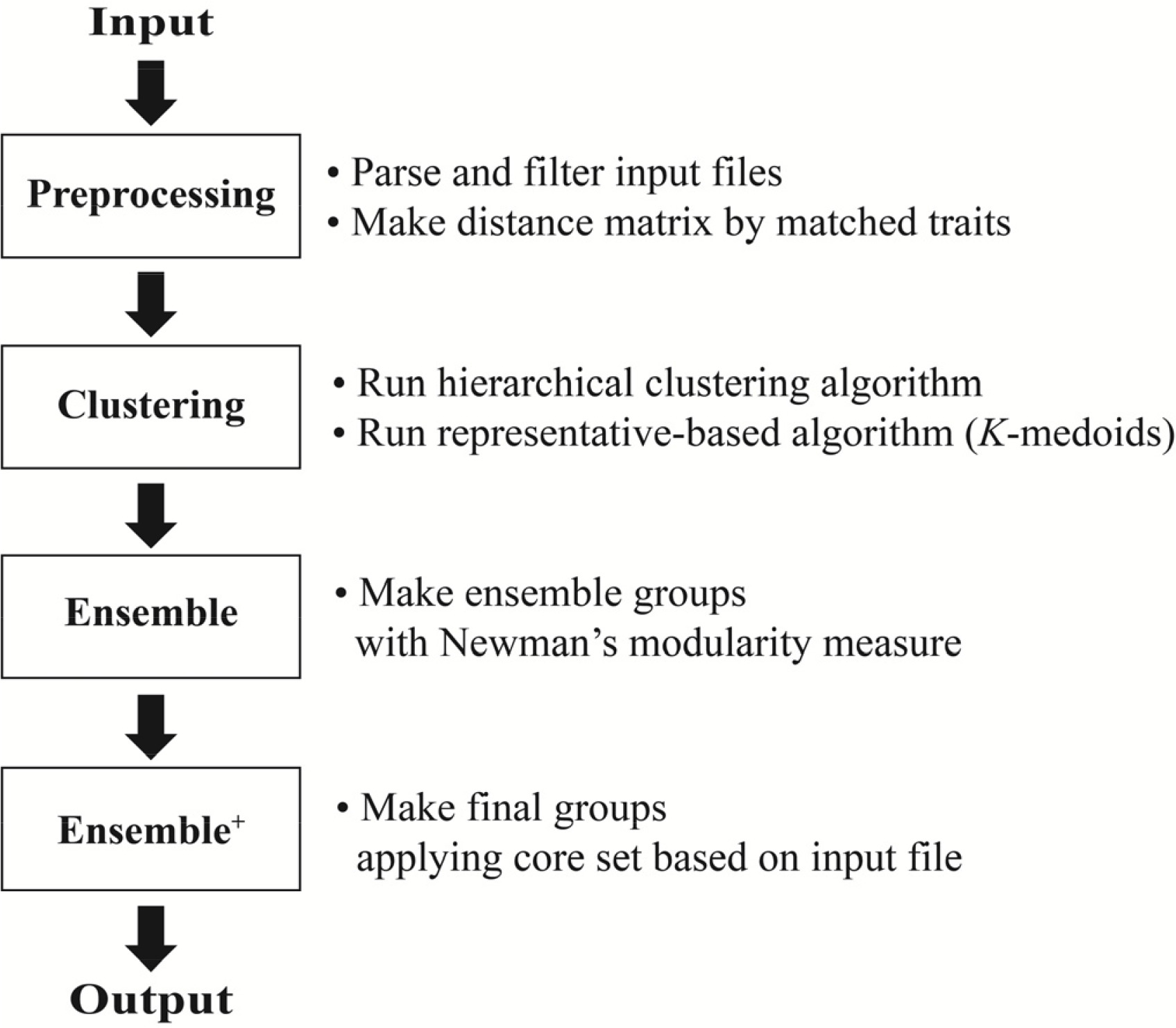
식물유전자원을 분류하기 위하여 cacGMS 알고리즘은 자원 간의 차이를 거리행렬(distance matrix)로 계산하는 전처리 단계(Preprocessing)와 계산된 행렬을 바탕으로 계층적 군집 알고리즘과 대표객체 기반 알고리즘으로 자원 군집화(Clustering), 군집된 자원 재구성(Ensemble) 및 핵심집단을 적용(Ensemble
+)하는 단계로 진행된다(
Fig. 1).
전처리 단계는 각 자원에 대한 범주형 자료로 구성된 특성평가 정보를 기반으로 각 자원 간의 거리행렬(distance matrix)을 계산한다. 유전자원의 특성평가 정보는 자료의 형태에 따라서 연속된 구간의 수치(연속형)나 셀 수 있는 숫자(이산형)로 표현되는 수치형과 특정 범주로 구분한 범주형을 포함하고 있다. 예를 들어 고추작물의 특성평가 정보는 초장, 추경장, 과폭, 과장, 엽장, 엽폭 등은 연속된 숫자로 표현되는 수치형 특성평가 정보와 옆색, 종자색, 화색, 과형, 초형, 착과형태, 등은 특정 범위로 구분된 명목형 특성평가 정보, 그리고 발병률(%), 병 저항성(%) 등과 같이 연속형으로 표현되는 자료임에도 생물학적 의미에 따라 범위를 정의하여 순서가 있는 범위로 구분한 순서형 특성평가 정보를 포함하고 있다. 그런데 수치형 자료는 초장, 엽폭, 종자 수 등과 같은 양적 형질의 자료형이 대부분으로 환경적 영향에 의해 관측치의 변동으로 분석결과의 부정확성이 발생할 수 있다(
Chung & Kim 2017). 더욱이 수치형 특성평가 정보에서 결측치가 다수 존재하는 경우에는 해당 값을 추정하기가 어렵다. 반면에 범주형 특성평가 정보는 순서형과 명목형을 포함하며 전문가의 의견을 수렴하여 범위를 구분하였기 때문에, 비록 정보의 손실을 감안하더라도 생물학적 근거를 바탕으로 군집할 수 있고 결측치가 존재하더라도
식 1과 같이 자원의 특성 비교를 통해서 두 자원 간의 유사성을 추정할 수 있다. 따라서 cacGMS 알고리즘은 자원 와 에서 공통으로 측정된 범주형 특성평가 정보(
Ni,j)가운데, 서로 일치하는 특성평가 정보(
T) 수의 비율(
Si,j,
식 1)로 계산하고,
식 2와 같이 거리 값으로 변환하여 거리행렬()을 완성한다. 두 자원 사이에서 결측된 정보가 적을 수록, 는 높아지게 되므로 두 자원 간의 유사도와 거리 값에 대한 신뢰성은 높아지게 된다. 참고로 결측치가 있는 연속형 자료의 경우에도 범주형으로 변환한다면 본 알고리즘으로 계산할 수 있다.
전처리된 자원은 계층적 군집 알고리즘과 대표객체 기반 알고리즘을 실행하는 군집단계(Clustering), 각 알고리즘의 군집결과를 재조합하는 단계(Ensemble), 그리고 핵심집단을 적용하는 단계(Ensemble+)로 진행된다.
군집단계에서는 계산된 거리행렬에 대하여 cacGMS 알고리즘은 Ward2 방법(
Murtagh & Legendre 2011)을 이용한 계층적 군집 분석과
K-medoids 알고리즘을 이용한 대표객체 기반 군집 알고리즘으로 유전자원을 분류한다(
Murtagh & Legendre 2011 Park & Jun 2009). 계층적 군집 분석은 덴드로그램(dendrogram)을 이용하여 계층적인 구조로 데이터를 구성함으로써 시각적으로 군집의 구분이 용이하며, 대표객체 기반 알고리즘의
K-medoids는 이상치나 잡음이 많은 자료에 적합한(
Arora et al. 2016) 알고리즘으로 cacGMS에 적용하였고, 각각 R 프로그램의 factoextra 라이브러리(
Kassambara & Mundt 2017) 와 cluster 라이브러리(
Maechler et al. 2013)를 사용하였다. 계층적 군집과 대표객체 기반 군집 알고리즘은 군집 수를 지정해야 하는데, 최적의 군집 수를 결정하기가 매우 어렵다 따라서 cacGMS 알고리즘은 지정된 범위 내에서 평균 실루엣 너비(Average Silhouette Width, ASW)가 높은 군집 수로 결정하였다(
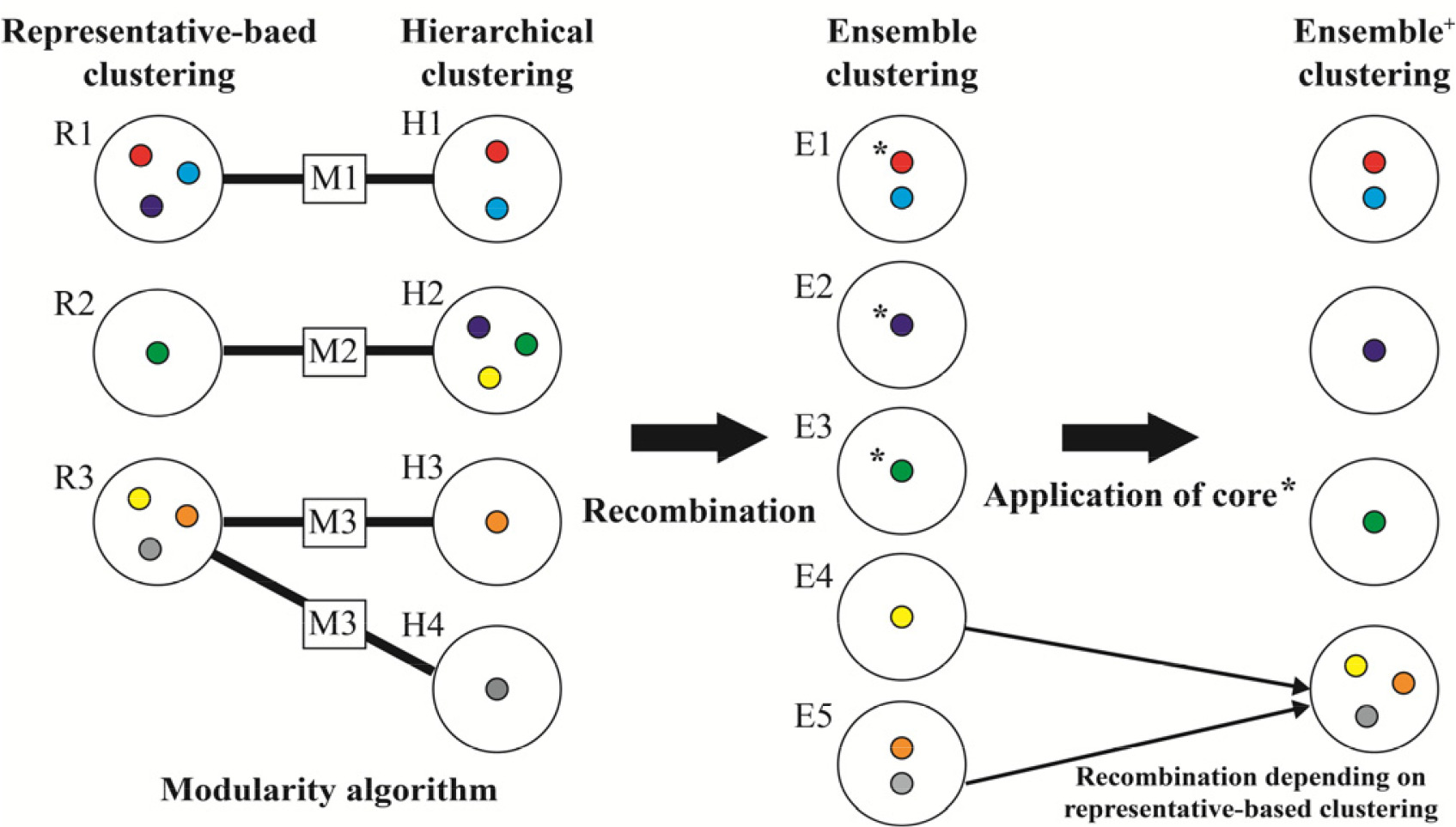
Rousseeuw 1987). Ensemble 단계에서는 두 알고리즘의 군집을 통합하는데, 각각의 알고리즘에 의한 군집 수와 군집 내 유전자원의 구성은 서로 차이가 나타날 수 있기 때문에, 이분그래프(bipartite) 평가방법인 Newman’s 모듈화(modularity) 기법에 기초하여 군집을 재조합한다(
Dormann 2020,
Dormann et al. 2021), 그리고 재조합된 군집은 핵심집단을 적용하여 최종적인 군집결과를 도출한다. 예를 들어
Fig. 2와 같이 계층적 군집과 대표객체 기반 알고리즘에 의한 군집이 모듈화 알고리즘에 의해 3개의 모듈(module)이 생성된 경우, cacGMS는 M1과 M2 모듈과 같이 두 알고리즘에 공통으로 포함하는 자원을 하나의 군집으로 조정하고 공통되지 않는 자원은 분리함으로써 군집을 재조합한다. 재조합 과정에서 M3의 H3과 H4는 R3와 비교하여 같은 군집인 E5로 통합되고, R3의 노란색 자원은 H3와 H4에 포함되지 않으므로 E4로 분리된다. 이 후 핵심집단 정보가 없을 경우에는 E1~E5 군집을 생성하며 알고리즘이 종료되고, 핵심집단 정보가 있다면 재조합된 군집 내에서 핵심집단 자원의 포함여부를 확인하여 Ensemble
+ 단계를 수행한다. 핵심집단의 자원이 포함된 Ensemble의 E1, E2, E3군집을 최종으로 결정하고, 핵심집단을 포함하지 않는 E4와 E5 군집은 알고리즘의 성능을 고려(
Gülagiz & Sahin 2017)하여 대표객체 기반 알고리즘 결과에 따라 군집을 다시 하나로 통합한다. 핵심집단은 자체 실험, 혹은 PowerCore (
Kim et al. 2007), Corehunter (
Thachuk et al. 2009)와 같은 프로그램으로 결정할 수 있는데 본 연구에서는 PowerCore 프로그램을 사용하여 알고리즘의 구동과 성능평가에 사용하였다.
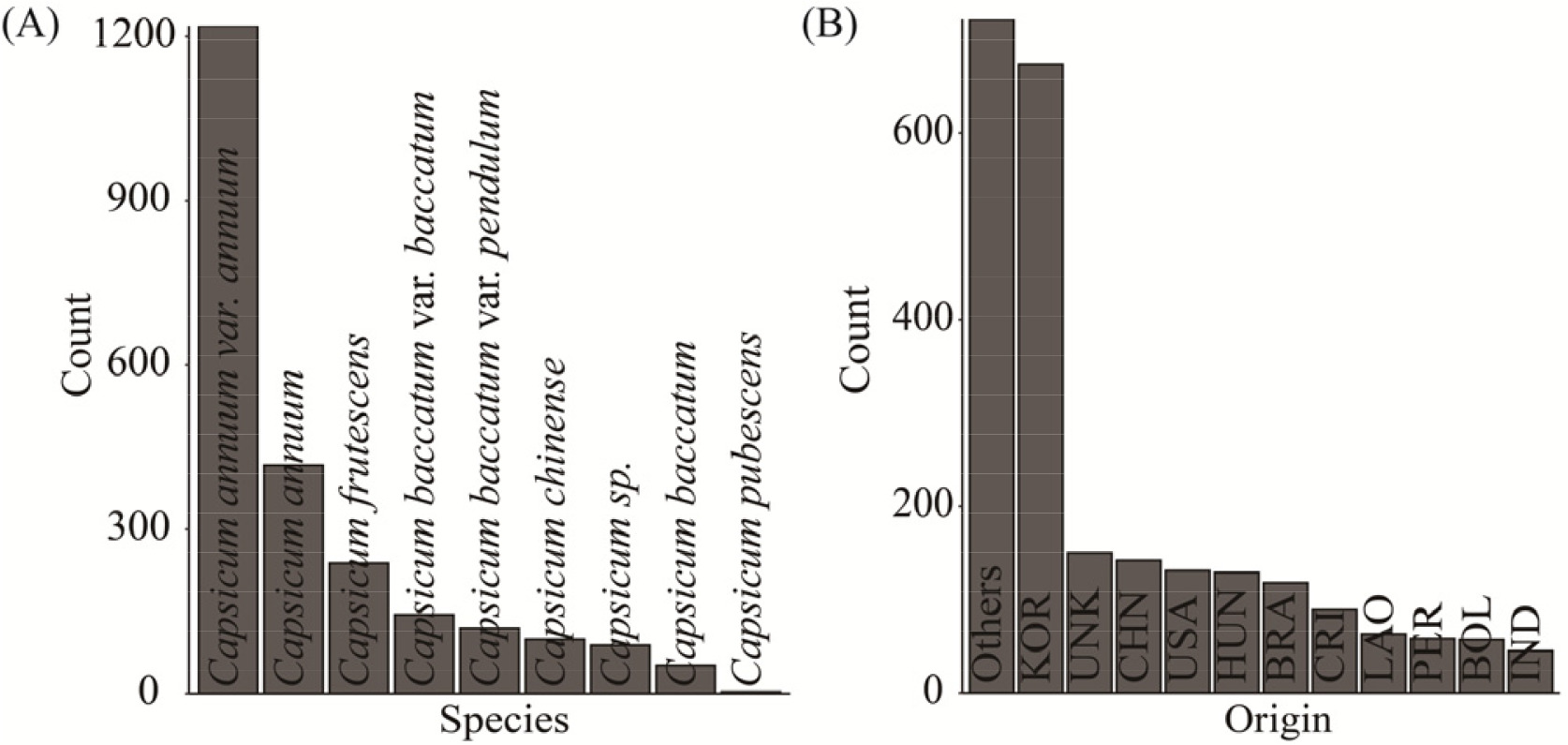
알고리즘의 성능평가에 이용된 고추 유전자원은 1990년 이후 특성평가 정보가 조사된 총 6,756 자원과 46개 범주형 특성평가 정보를 이용하여 시험하였다(
Supplementary Table 1). 사용된 고추 유전자원의 종과 원산지별 분포를 분석했을 때,
Capsicum annuum을 포함한 총 12종(
Fig. 3A)과, 총 114개국 원산지(
Fig. 3B)가 확인되었는데, 종 분포에 있어서는
Capsicum annuum var.
annuum이 가장 많은 수를 보였고 원산지는 한국(KOR)이 가장 많았다. 그리고 종과 원산지가 서로 유의적인 차이(Chi- square test,
p-value<0.05)로 나타났다. 따라서 유전자원의 특성이 종과 재배⋅증식되는 환경과 관련이 있다는 점에서 특성평가 정보에 기반한 군집은 종 분포와 원산지 분포가 유의적으로 차이가 있을 것과 각 특성평가 정보가 분류된 군집과 관계가 있을 것으로 가정할 수 있으므로 카이제곱 검정(Chi-square test) 방법의 유의수준(
p-value)을 통해 이들 관계를 검정하였다.
군집 알고리즘에 사용되는 범주형 특성평가 정보에 있어서, 줄기흰털, 엽색, 종자색, 과형, 착과형태 등을 포함한 다수의 평가 항목에는 기타나 혼립 같은 모호한 분류기준이 존재한다. 이는 자원의 다양성 및 특이성 판단, 증식/재배환경에 따른 이상형질 발생, 조사자의 주관적 의견 등으로 인하여 특성평가 정보가 정해진 분류기준에 부합하지 못한 경우에는 기타나 혼립으로 분류되지만, 기타나 혼립을 제외할 경우에는 해당 자원 정보의 소실이 우려된다. 따라서 본 연구에서는 현재 유전자원의 특성평가 정보를 최대한 활용하여 성능을 시험하고자 기타 및 혼립을 분석대상에서 제외하지 않았다. 그리고 군집 알고리즘을 실행할 때 사용한 특성평가 정보의 최소 수(Threshold)는 군집 간 평균 거리, 군집 내 자원의 거리, 엔트로피를 종합적으로 판단하여 18개(2,378 자원)로 지정하여 비교하였다. 하지만 특성평가 정보의 최소 수에 따라 사용되는 자원 수가 달라지는 점을 고려하여 추가 비교분석에서 특성평가 정보 수를 15개에서 30개로 변화시키면서 알고리즘의 성능 변화를 상호 비교하였다.
종, 원산지와의 관계, 특성평가 정보의 관계를 통한 알고리즘의 군집결과의 평가와 함께 자원의 밀집과 군집상태를 분석하여 알고리즘을 평가하기 위한 척도로써 군집 간의 분리성(separability), 군집 내 자원의 밀집성(compactness)과 동질성(homogeneity)을 측정하였다(
Kim 2012). 군집결과에 대한 분리성, 밀집성, 동질성은 각각 군집간 평균거리(Average between,
식 3), 군집 내 자원간 평균거리(Average within,
식 4), 엔트로피(Entropy,
식 5)로 평가할 수 있으므로(
Halkidi et al. 2002,
McClain & Rao 1975,
Meilă 2007), R 프로그램의 fpc 라이브러리를 이용하여 계산하였다(
Dessau & Pipper 2008,
Hennig 2015).
결과 및 고찰
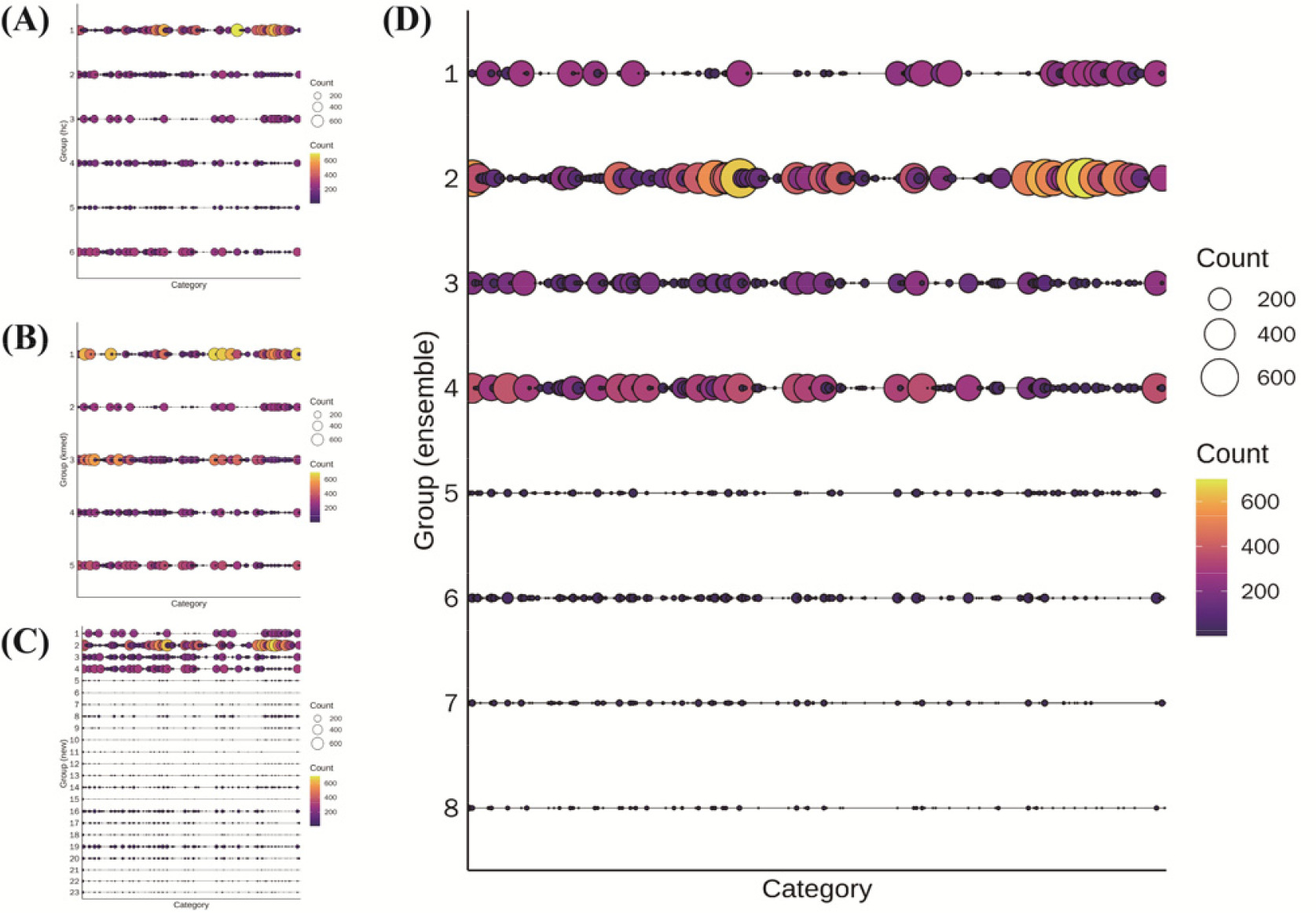
고추 2,378 유전자원(Threshold=18)을 대상으로 PowerCore에 의한 핵심집단 58개 자원과 함께 cacGMS 알고리즘을 수행했을 때, 계층적 군집 알고리즘은 6개, 대표객체기반 군집은 5개, 통합모형은 핵심집단을 제외했을 경우 23개, 핵심집단을 포함했을 경우 8개의 군집을 생성하였다(
Fig. 4). 특성평가 정보에 따른 자원 세분화는 Ensemble 단계에서 가장 크게 나타났고, 대표객체 기반 알고리즘이 가장 작았으며, 핵십집단을 적용한 군집(Ensemble
+)는 일부 세분화된 군집이 나타났다. 계층적 군집과 대표객체 기반 알고리즘의 군집 수가 적음에도 불구하고 cacGMS 알고리즘에 따른 Ensemble 단계에서 군집 수가 늘어난 것으로 볼 때, 각 알고리즘에 의한 군집 내의 자원이 서로 차이가 있음을 유추할 수 있다.
특성평가 정보에 따른 군집화에 있어서 종은 자원의 계통분류학적 특성을 나타내며, 원산지는 자원의 생태적 환경을 의미하므로, 특성평가 정보에 의한 군집화는 종과 원산지의 차이가 반영되어야 한다. 이를 확인하고자 종과 원산지 분포에 대해서 각 군집 알고리즘의 카이제곱 검정(Chi-square test) 결과는 모두 유의적인 관계(
p-value<0.05)를 보여주었다(
Table 1). 따라서 계층적 군집, 대표객체 기반, 그리고 cacGMS 알고리즘에 의한 군집은 종과 원산지 분포에 대하여 무관하지 않음을 추정할 수 있고, 이를 근거로 군집 정보를 바탕으로 특성평가 정보와 함께 종, 원산지를 이용한 연구에 활용할 수 있다.
군집 알고리즘은 사용된 특성평가 정보를 기반으로 자원들이 분류되었기 때문에, 군집결과에 특성평가 정보의 차이가 반영되었는지를 확인함으로써 군집 결과에 대한 성능을 유추할 수 있다. 따라서 각 알고리즘에 의해 분류된 자원의 군집과 46개 특성평가 정보의 차이를 카이제곱 검점으로 시험했을 때, 대부분 유의적인 차이가 있었다(
p-value<0.05). 그러나
Table 2와 같이 담배모자이크 바이러스(연번 24)와 흰가루병 발병률(연번 31), 신미정도(연번 45)는 모든 알고리즘이 공통적으로 유의적 차이가 확인되지 않았고, 일부 특성평가 정보에 대해서는 유의적 차이가 알고리즘마다 다른 것으로 보아 일부 특성평가 정보는 군집분류에 반영이 되지 않았음을 알 수 있다. 그런데 각 알고리즘 간의 비교에서 특성평가 정보가 미 반영된(
p-value>0.05) 개수가 Ensemble
+은 가장 낮은 4개이고, 계층적 군집 알고리즘과 대표객체 기반 알고리즘은 각각 6개, 8개로 확인되어 Ensemble
+의 군집결과가 다른 알고리즘보다 좀 더 반영되었음을 추정할 수 있다.
각 알고리즘별로 자원 군집의 적절성을 추정하기 위하여 군집간 평균거리, 군집내 자원 간 평균거리와 엔트로피로 비교하였다 (
van den Hoven 2015). 그 결과, cacGMS 알고리즘이 군집 간 평균거리와 엔트로피에서는 가장 좋은 결과를 보였고, 계층적 군집 알고리즘은 군집내 자원간 평균거리에서 성능이 좋은 것으로 확인되었다(
Table 3). 이 결과로부터 유사한 자원 간의 밀집성은 계층적 군집 알고리즘에서 우수하지만 군집 간의 분리성과 자원 간의 동질성에 있어서는 cacGMS 알고리즘의 Ensemble
+ 성능이 우수함을 알 수 있었다. 그리고 Ensemble은 가장 많은 군집이 확인되었음에도 분리성에서 Ensemble
+와 함께 타 알고리즘보다 성능에서 우수함을 보였지만, 군집 수가 높은 것은 Ensemble
+ 군집이 세분화된 결과로 판단할 수 있다.
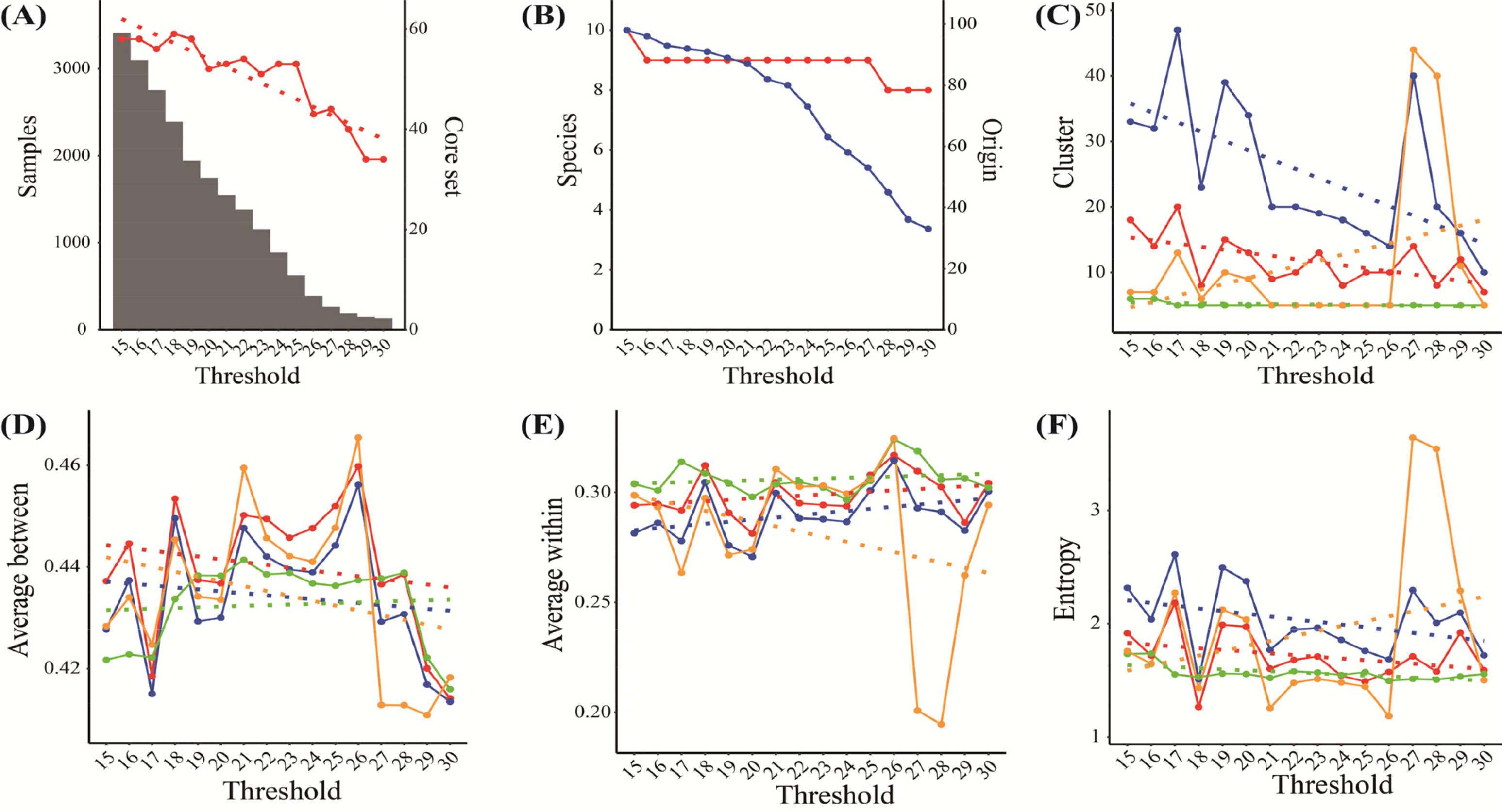
추가로 활용가능한 특성평가 정보의 최소 수를 15~30개로 변경하면서 성능을 분석하였다.
Fig. 5와 같이 각 제한되는 정보에 따라서 자원 수, PowerCore에 의한 핵심집단 수, 원산지 수는 자원의 수에 따라 감소하여 군집 수도 점진적으로 감소할 것으로 예상할 수 있다(
Figs. 5A,
5B). 그런데,
Fig. 5C에서와 같이 cacGMS알고리즘의 군집의 수는 최소 수 증가에 따라 감소하지만, 계층적 군집 알고리즘은 특정 조건(Threshold=28, 29)에서 군집 수가 증가하였고, 군집간 평균 거리와 엔트로피가 특이적으로 나타났다. 그리고 대표객체 기반 알고리즘은 최소 수와 핵심집단의 수, 원산지 수의 감소 변화에 관계없이 군집 수가 거의 변하지 않았으며, 군집 간 평균거리, 군집 내 자원간 평균거리, 엔트로피에서 낮은 성능을 보였다. 따라서 cacGMS 알고리즘은 계층적 군집과 대표객체 기반 알고리즘보다 자원의 군집 분류 성능이 우수함을 추정할 수 있다.
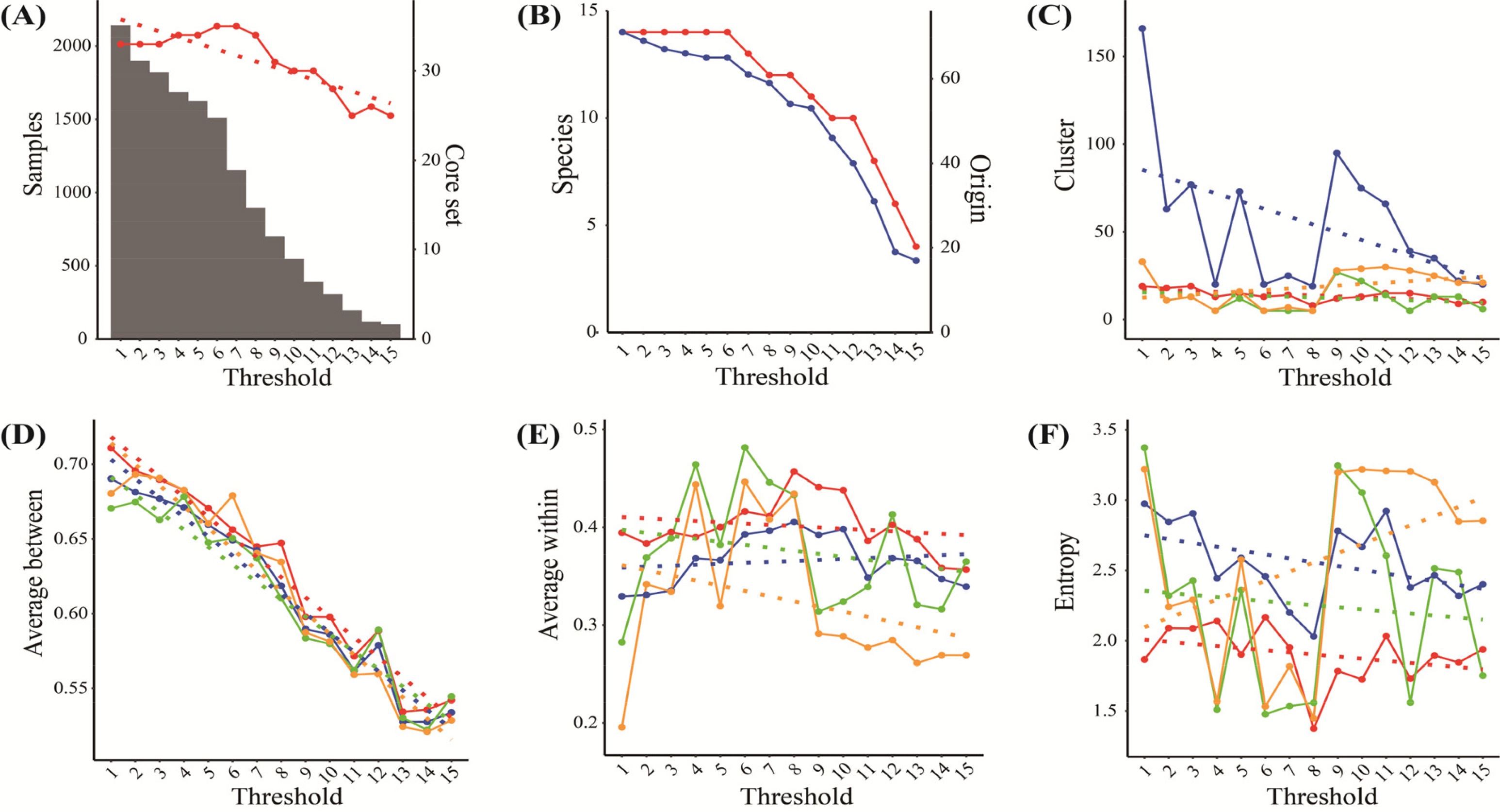
고추 유전자원 외에 토마토 2,191 유전자원을 대상으로 미숙과색, 과피색, 세로 과실모양 등, 24개 범주형 특성평가 정보를 사용하여 동일한 방법으로 시험했을 때, 고추 유전자원과 마찬가지로 제한된 특성평가 정보에 따라서 군집간 평균 거리와 엔트로피에서 핵심집단을 적용한 cacGMS 알고리즘(Ensemble
+)이 우세하게 나타났다(
Fig. 6). 따라서 범주형 특성평가 정보를 이용한 유전자원 분류에서 cacGMS 알고리즘이 유용함을 확인할 수 있었다.
군집 알고리즘의 활용적 측면에서, 다수의 유전자원에 대한 군집화는 개체 간의 유사성 및 집단의 대표성 분석, 집단의 우점 정도 및 특이적 집단 분류, 군집별 특성 분석에 사용할 수 있고, 생물학적 혹은 작물 다양성 분석, 특이적 특성 도출 등과 같은 유전자원 활용 연구를 위한 의미있는 정보의 생산에 이용되고 있다. cacGMS 알고리즘은 특성평가 정보를 활용하여 유사한 자원을 군집단위로 분류함으로써, 군집 내 유사특성의 자원을 동정하고 특이적 자원 선발을 위한 유전자 마커(Genetic marker) 개발(
Odong et al. 2011), 종, 원산지, 유전적 다양성 분석(
Chen & Nelson 2005), 품종육성을 위한 자원선발과 같은 육종연구에의 활용(
Lee et al. 2021), 그리고 개별적으로 선발된 핵심집단과 함께 집단을 중심으로 다양한 특성의 유전자원을 효율적으로 관리하고 보존할 수 있는 체계를 확립하는데 활용할 수 있다. 향후 정보에 대한 질적 향상과 함께 연속형과 이산형을 포함한 수치형 특성평가 정보의 결측치를 보완하고 전문가에 의해 범주형으로 변환하여 본 알고리즘에 적용하게 된다면, 기후변화, 경작지 환경을 포함하는 농업생태계 변화에 적응하는 유전자원 특성을 연구하는 것과 같이 다양한 농업분야(
Jarvis et al. 2010)에 활용될 수 있을 것이다.
적 요
식물 유전자원은 종자를 포함하여 뿌리, 잎, 줄기와 같은 식물의 일부분이 재배 및 증식에 활용될 수 있는 자원으로, 생태적 생물다양성을 유지하고 안정적인 작물생산과 보급을 위하여 보존 및 관리되어야 한다. 형태적, 유전적 특성에 따라 식물 유전자원은 다양하게 분류할 수 있는데, 유사한 특성에 따라 유전자원을 분류함으로써 효율적인 자원관리, 대표성 검토, 유용한 형질의 유사자원을 이용한 다양한 품종개량 등에 활용할 수 있다. 본 연구는 식물의 종피색, 화색, 종자형태 등과 같은 범주형 자료를 대상으로 유전자원을 분류하는 cacGMS (Clustering Analysis for Categorical genetic traits of germplasms in Genebank Management System) 알고리즘을 개발하였다. cacGMS는 R 패키지의 Ward2 방법을 이용한 계층적 군집 알고리즘과 K-medoids 알고리즘과 같은 대표객체 기반 알고리즘을 통합하여 핵심집단을 적용함으로써 유전자원을 분류한다. 본 알고리즘의 성능을 평가하기 위하여 씨앗은행에서 제공하는 고추의 46개 범주형 특성평가 정보를 사용하여 고추 2,378 유전자원을 시험했을 때, 군집간 평균거리와 엔트로피에서 각각 0.4534, 1.2672로 계층적 군집 알고리즘과 대표객체 기반 알고리즘보다 성능이 우수함을 보였으며, 토마토 유전자원에서도 cacGMS 알고리즘의 효용성을 입증하였다. 본 알고리즘을 통해서 특성평가 정보에 따른 수많은 유전자원을 효율적으로 보존하고 관리할 수 있을 것이며, 유전자원을 활용한 데이터베이스 구축과 육종개발을 통한 신품종 개발, 식물 유전자원의 표현형과 유전자형과의 연관분석 등 다양한 연구에 활용될 수 있을 것으로 기대한다.
보충자료
본문의 Supplementary Table 1은 한국육종학회 홈페이지에서 확인할 수 있습니다.
사 사
본 연구는 농촌진흥층 연구과제 ‘유전자원 활용도 제고를 위한 DB화 및 서비스(PJ014226)’의 지원을 받아 수행하였습니다.
Fig. 1Pipeline of cacGMS algorithm.
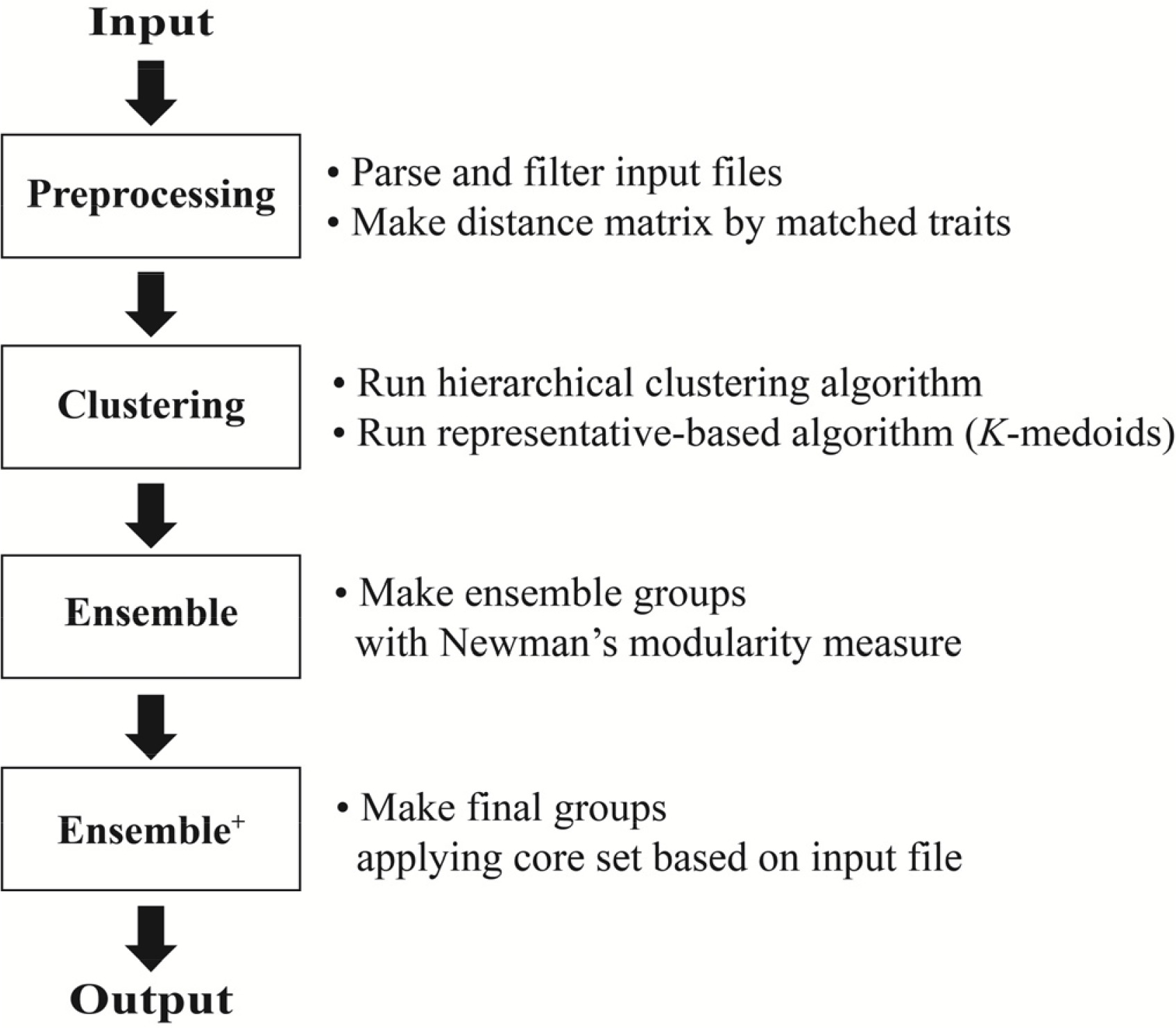
Fig. 2Example for the ensemble and ensemble+ clustering method.
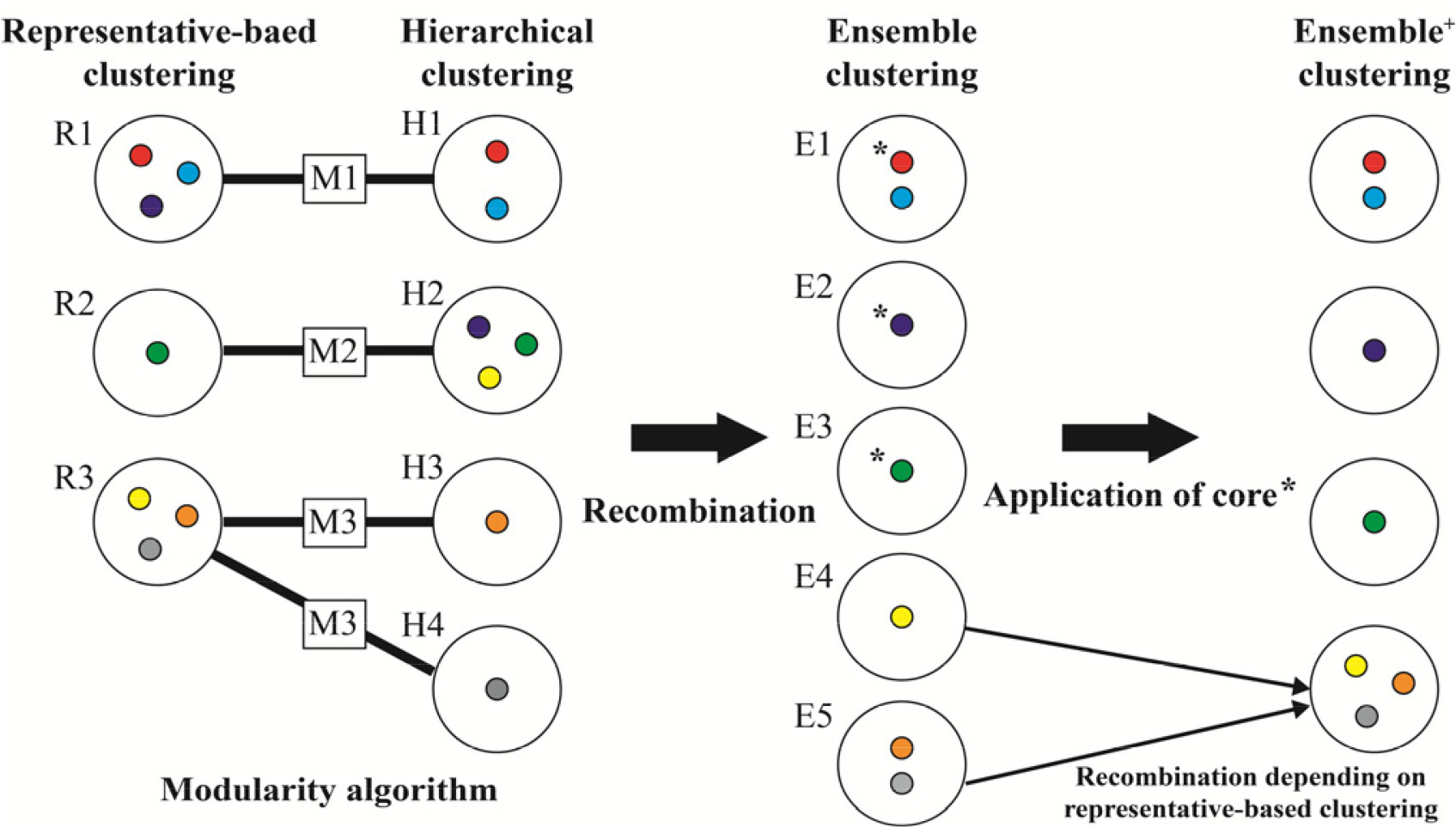
Fig. 3Distribution of species (A) and origin (B).
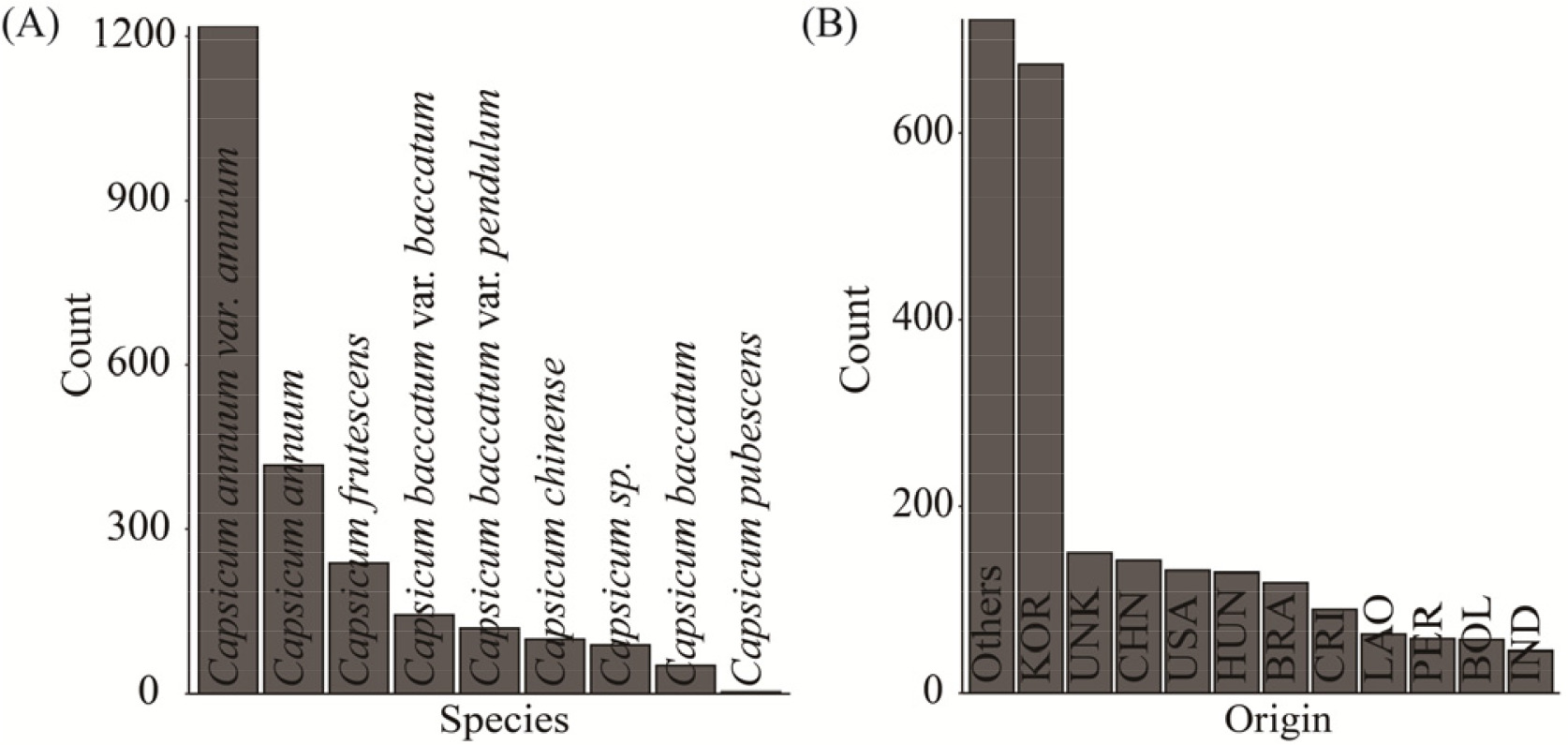
Fig. 4Groups clustered by hierarchical (A), representative-based algorithm (B), Ensemble (C), and Ensemble+ (D) with threshold= 18; x-axis, category (46 genetic traits); y-aixs, cluster number.
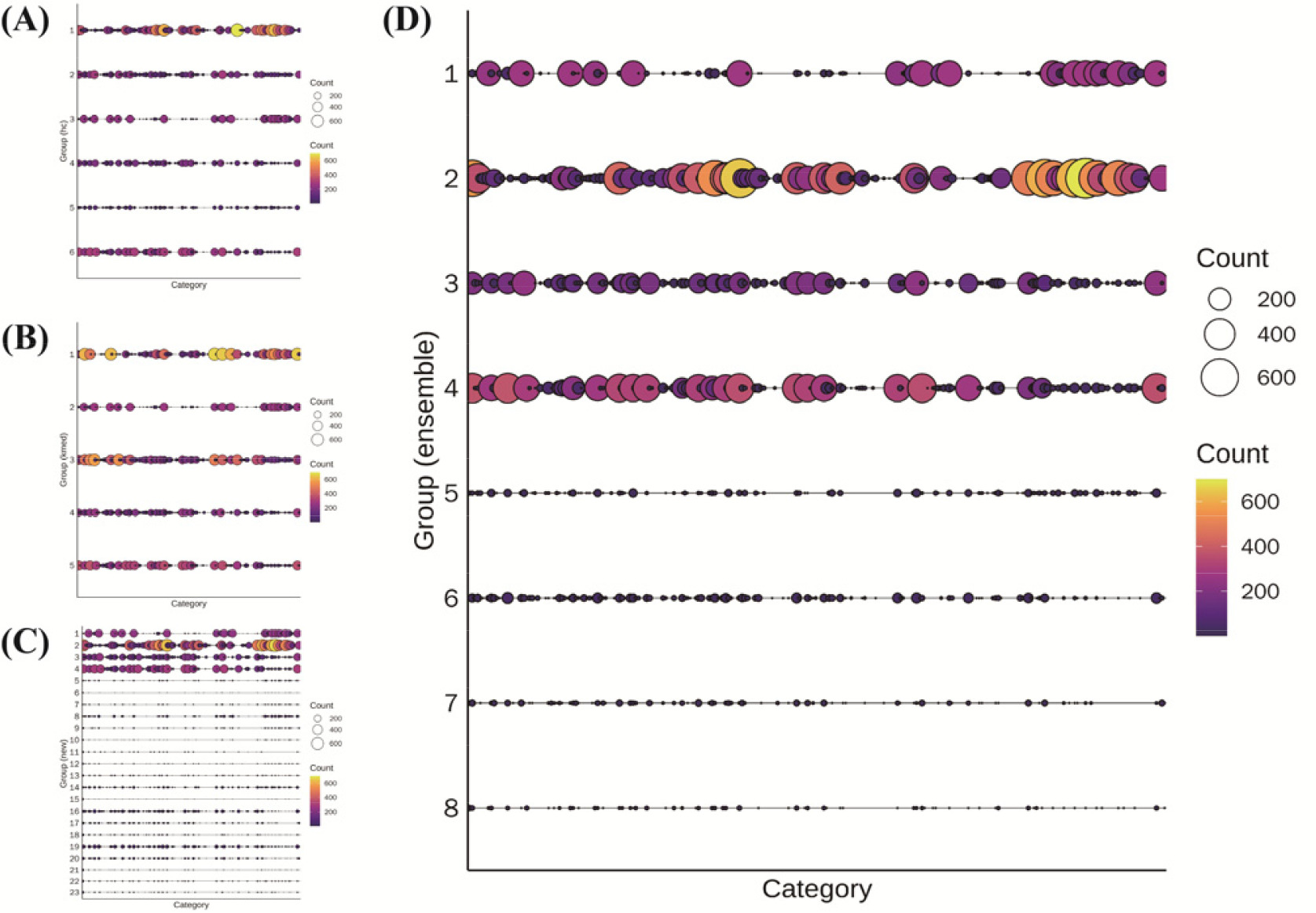
Fig. 5Pepper genetic resources’ distribution and clusters’ estimation by threshold (the number of genetic traits); A, Sample (bar) and Core set (red); B, Species (red) and Origin (blue); C~F, the number of clusters (C), average between (D), average within (E), and entropy (F) by ensemble+ (red), ensemble (blue), representative-based (green), and hierarchical algorithm (orange) including linear regression (dot-line).
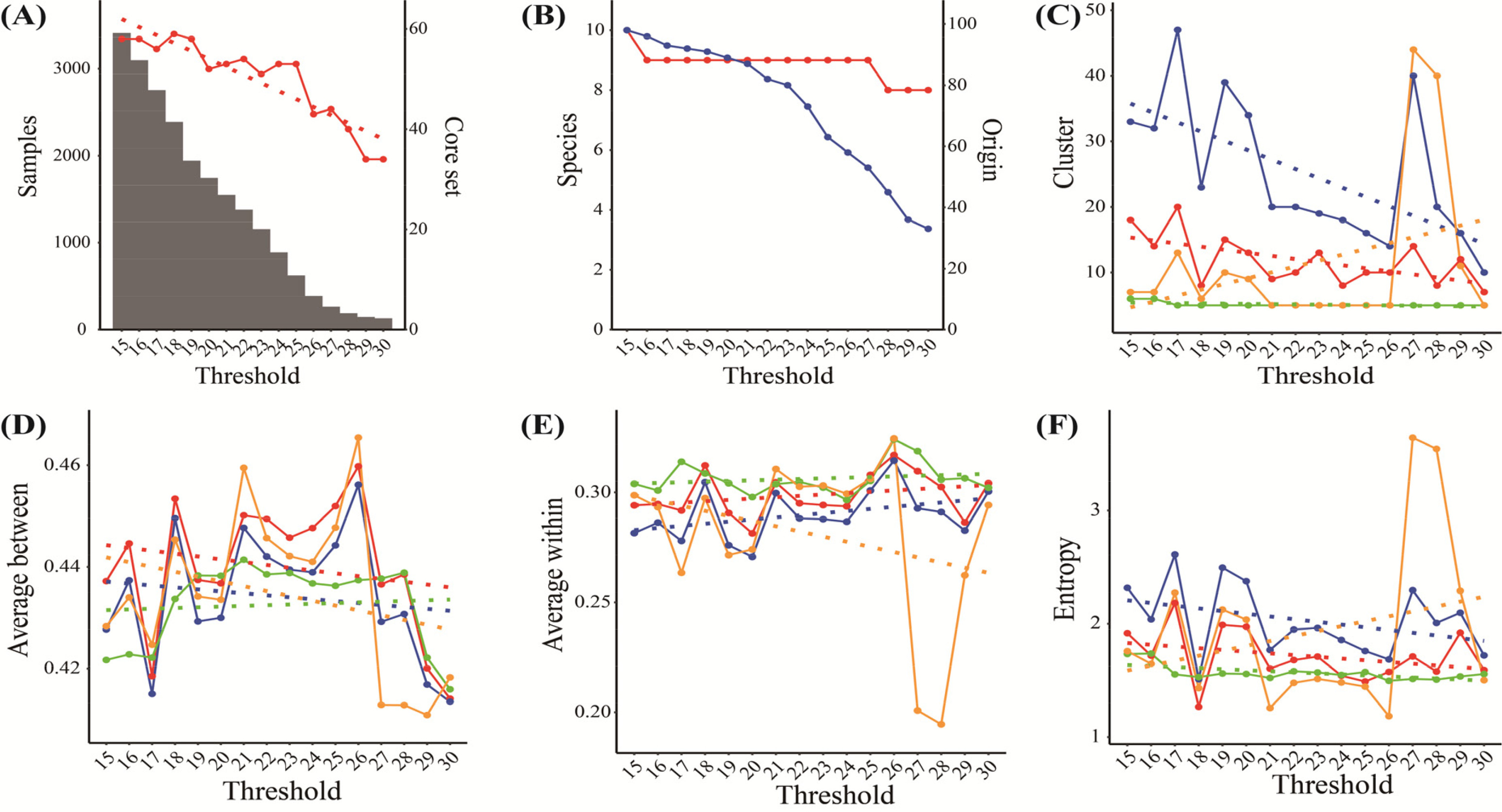
Fig. 6Tomato genetic resources’ distribution and clusters’ estimation by threshold (the number of genetic traits); A, Sample (bar) and Core set (red); B, Species (red) and Origin (blue); C~F, the number of clusters (C), average between (D), average within (E), and entropy (F) by ensemble+ (red), ensemble (blue), representative-based (green), and hierarchical algorithm (orange) including linear regression (dot-line).
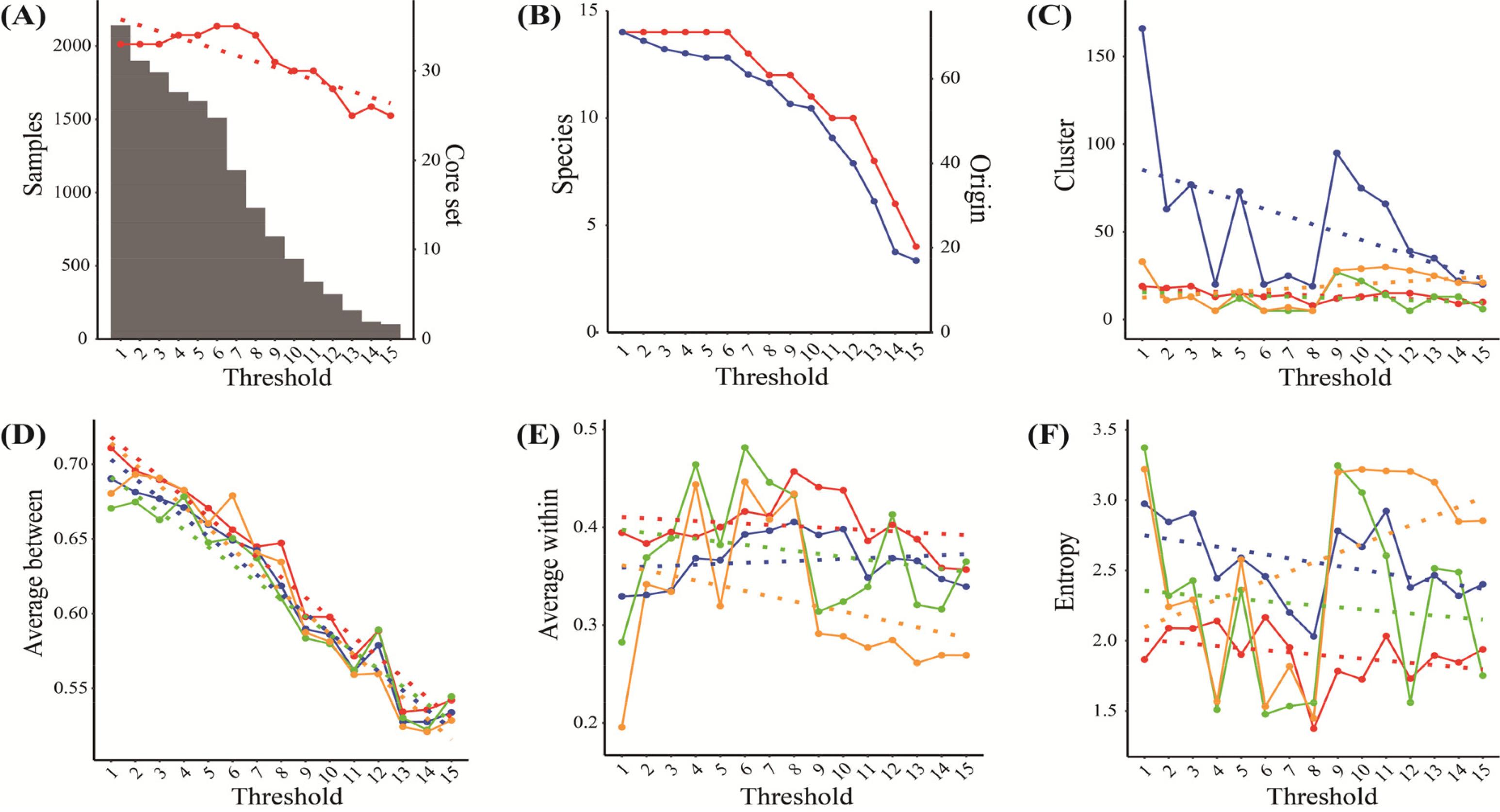
Table 1Chi-square test for each algorithm against species and origin
Table 1
|
Algorithm |
Section |
Statistic |
Degree of freedom |
p-value |
|
Ensemble+
|
Species |
3778.16 |
56 |
<0.01 |
|
Origin |
2657.68 |
644 |
<0.01 |
|
Ensemble |
Species |
4413.43 |
176 |
<0.01 |
|
Origin |
7449.45 |
2024 |
<0.01 |
|
Hierarchical algorithm |
Species |
4948.50 |
40 |
<0.01 |
|
Origin |
3357.02 |
460 |
<0.01 |
|
Representative-based algorithm |
Species |
3117.55 |
32 |
<0.01 |
|
Origin |
2535.04 |
368 |
<0.01 |
Table 2Genetic traits with chi-square test, p-value>0.05
Table 2
|
No. |
Genetic traits (in Korea) |
Ensemble+
|
Ensemble |
Hierarchical algorithm |
Representative-based algorithm |
|
11 |
Male sterility |
*
|
***
|
*
|
++ |
|
20 |
Cotyledon color |
***
|
***
|
***
|
+ |
|
24 |
Incidence rate of tobacco mosaic virus |
++ |
++ |
++ |
++ |
|
25 |
Incidence rate of cucumber mosaic virus |
***
|
***
|
++ |
++ |
|
30 |
Incidence rate of tomato spotted wilt virus |
**
|
++ |
++ |
++ |
|
31 |
Incidence rate of powdery mildew |
++ |
++ |
++ |
++ |
|
32 |
Incidence rate of bacterial wilt (index) |
*
|
+ |
***
|
**
|
|
40 |
Resistance of pepper bacterial spot (Bs2) |
***
|
***
|
++ |
***
|
|
43 |
Resistance of potyvirus(pvr2) |
**
|
+ |
*
|
*
|
|
44 |
Resistance of potyvirus(pvr4) |
++ |
*
|
*
|
++ |
|
45 |
Hot-taste level |
++ |
++ |
++ |
++ |
|
No. genetic traits (p-value>0.05) |
4 |
6 |
6 |
8 |
Table 3Estimation for clustering algorithm with threshold 18 (≤ available genetic traits)
Table 3
|
Method |
Ensemble+
|
Ensemble |
Hierarchical algorithm |
Representative-based algorithm |
|
Cluster |
8 |
23 |
6 |
5 |
|
Average between |
0.4534
|
0.4496 |
0.4454 |
0.4337 |
|
Average within |
0.3122 |
0.3046 |
0.2974
|
0.3086 |
|
Entropy |
1.2672
|
1.5114 |
1.4326 |
1.5301 |
References
- Arora P, Deepali , Varshney S. 2016. Analysis of K-means and K-medoids algorithm for big data. Procedia Comput Sci 78: 507-512.
- Chen Y, Nelson RL. 2005. Relationship between origin and genetic diversity in Chinese soybean germplasm. Crop Sci 45: 1645-1652.
- Chung IK, Kim K-M. 2017. QTL Analysis of concerned on ideal plant form in rice. Korean J Plant Res 30: 213-218.
- Dessau RB, Pipper CB. 2008. "R"-project for statistical computing. Ugeskrift for Laeger 170: 328-330.
- Dormann CF. 2020. Using bipartite to describe and plot two-mode networks. R. R-project.
- Dormann CF, Fruend J, Gruber B, Dormann MCF, LazyData T, ByteCompile T. 2021. Package 'bipartite'. R-project, https://cran.r-project.org.
- Gülagiz FK, Sahin S. 2017. Comparison of hierarchical and non-hierarchical clustering algorithms. Int J Comput Eng Inf Technol 9: 6-14.
- Halkidi M, Batistakis Y, Vazirgiannis M. 2002. Cluster validity methods: Part I. ACM Sigmod Record 31: 40-45.
- Hennig C. 2015. fpc: Flexible procedures for clustering. R-project, https://cran.r-project.org.
- Hintum vTJ, Brown A, Spillane C. 2000. Core collections of plant genetic resources. Bioversity International, pp. 6-8.
- Hoven Jvd. 2015. Clustering with optimised weights for Gower's metric. Amsterdam University.
- Jarvis DI, Padoch C, Cooper HD. In: Jarvis DI, Padoch C, Cooper HD. 2010. Managing biodiversity in agricultural ecosystems [Korean version]. (Eds). Biodiversity, agriculture, and ecosystem services. Columbia University Press, New York, USA: pp. 19-29.
- Kassambara A, Mundt F. 2017. Package 'factoextra'. R- project.
- Kim CY, Lee JR, Yoon MS, Cho GT, Baek HJ, Ko HC, Cho YH, Jeon YA, Kim CK. 2010. Present status and future perspectives for the use of genetic resources in Korean agriculture. J Korean Soc Int Agric 22: 231-240.
- Kim K-W, Chung H-K, Cho G-T, Ma K-H, Chandrabalan D, Gwag J-G, Kim T-S, Cho E-G, Park Y-J. 2007. Powercore: A program applying the advanced M strategy with a heuristic search for establishing core sets. Bioinformatics 23: 2155-2162.
- Kim K. 2012. Fn-measure: An external cluster evaluation measure. J Soc Korea Ind Syst Eng 35: 244-248.
- Lee JY, Choi HJ, Son CK, Bae JS, Jo H, Lee J-D. 2021. Genetic diversity of black soybean germplasms with green cotyledon based on agronomic traits and cotyledon pigments. Korean J Breed Sci 53: 127-139.
- Maechler M, Rousseeuw P, Struyf A, Hubert M, Hornik K, Studer M. 2013. Package 'cluster'. R-project, https://cran.r-project.org.
- McClain JO, Rao VR. 1975. Clustisz: A program to test for the quality of clustering of a set of objects. J Mark Res 12: 456-460.
- Meilă M. 2007. Comparing clusterings-an information based distance. J Multivar Anal 98: 873-895.
- Moe KT, Gwag J-G, Park Y-J. 2012. Efficiency of powercore in core set development using amplified fragment length polymorphic markers in mungbean. Plant Breed 131: 110-117.
- Murtagh F, Legendre P. 2011. Ward's hierarchical clustering method: Clustering criterion and agglomerative algorithm. ArXiv abs/1111.6285.
- Murtagh F, Legendre P. 2014. Ward's hierarchical agglomerative clustering method: Which algorithms implement ward's criterion? J Classif 31: 274-295.
- Nicotra AB, Atkin OK, Bonser SP, Davidson AM, Finnegan EJ, Mathesius U, Poot P, Purugganan MD, Richards CL, Valladares F, Kleunen vM. 2010. Plant phenotypic plasticity in a changing climate. Trends Plant Sci 15: 684-692.
- Odong TL, Heerwaarden vJ, Jansen J, Hintum vTJL, Eeuwijk vFA. 2011. Determination of genetic structure of germplasm collections: Are traditional hierarchical clustering methods appropriate for molecular marker data? Theor Appl Genet 123: 195-205.
- Oh SY. 2014. Access to plant genetic resources and its benefit sharing system - Focusing on the relationship between Nagoya protocol and ITPGRFA agreement -. Environ Law Rev 36: 213-233.
- Park H-S, Jun C-H. 2009. A simple and fast algorithm for K-medoids clustering. Expert Syst Appl 36: 3336-3341.
- Rousseeuw PJ. 1987. Silhouettes: A graphical aid to the interpretation and validation of cluster analysis. J Comput Appl Math 20: 53-65.
- Thachuk C, Crossa J, Franco J, Dreisigacker S, Warburton M, Davenport GF. 2009. Core hunter: An algorithm for sampling genetic resources based on multiple genetic measures. BMC Bioinform 10: 243-255.
- Xepapadeas A, Ralli P, Kougea E, Spyrou S, Stavropoulos N, Tsiaousi V, Tsivelikas A. 2014. Valuing insurance services emerging from a gene bank: The case of the Greek gene bank. Ecol Econ 97: 140-149.